一次常见的 404 错误引发的致命级删库灾难

文章目录
【注意】最后更新于 December 3, 2021,文中内容可能已过时,请谨慎使用。
起因
2021年12月2日 15: 02 时间,本应该是一如既往、平平淡淡(划水摸鱼,哦不,努力搬砖的一天),突然企业群内收到消息,CS反馈,代理商新发布的房子无法访问404了,作为一个开发老司机,这种小事简直 so easy。
于是就把这个问题,交给了一位后端同事去排查具体原因,经过一顿猛如虎的操作,确定是我们所在日本区的数据库数据无法正常的将数据同步到中国区导致的。
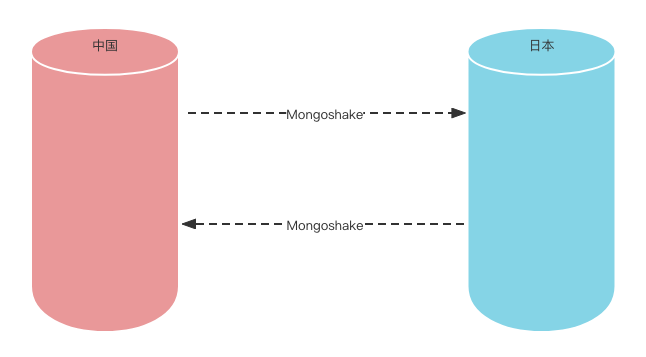
说到这里就不得不提,我司的牛逼架构设计,两地跨国数据库双向同步设计,简称异地双向同步:
本来这个同步架构设计好,启动后,并未出现过任何问题,如图:
现在这样了,从日本到中国的同步的出现错误了。
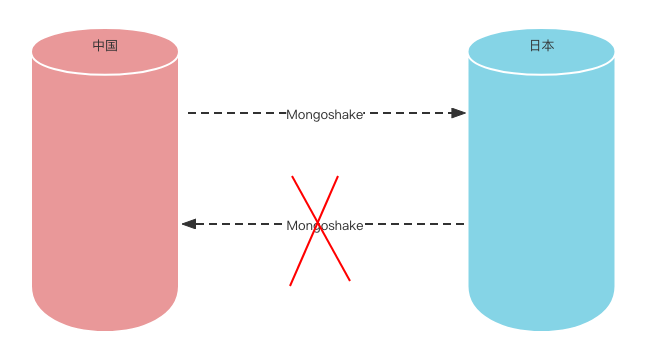
原因
为了保证我们在中国和国外的访问速度,我们分别部署了2地数据库服务,保证这个双向数据同步的服务是 MongoShake ,可以确认的是它的一条同步进程崩了,也就是日本区向中国区同步的这条腿阙了,同时,在 log 中还发现了大量的错误语句:oplog syncer internal error: collection capped error。
写这个开源项目的攻城狮还真可爱,大意是说:oplog 内部发生了错误,有个东西满了,老子没办法处理了,该你动手了。又经过一顿猛如虎的源码查找。经过仔细琢磨与推敲,我们似乎找到了问题原因。
oplog的大小是固定的,几日前同事手动瘦身了一张亿级Log表,一下就删除了千万条数据,大量oplog的写入导致了还未同步的oplog就被新产生的oplog 给覆盖了。
mongoshake 每同步一批数据就会记录一个时间点位(ckpoint),下一次同步时就以为这个时间点作为起点查找下一批待同步的oplog 进行同步,当它根据这个时间去查找oplog时,发现这个时间没了 ,于是就抛出那样一句话。
解决
经过慎重的琢磨,我们解决方案是,重新配置一下日本到中国区的同步进程,跳过那个已经找不到的时间点位(ckpoint),重新启动服务,不就可以了嘛。
说时迟那时快,三下五除二很快就配置好了,鸡冻的心颤抖的手,按下 Enter 终于又再次启动同步进程的命令,准备查看一下同步情况。
我靠, 数据库呢?What the fuck!!! (握了一棵小草) 数据去哪里了?三个库、百张表、100GB数据去哪里了?手心瞬间一阵冷汗,于是赶紧查看网站、 APP,擦!!!数据全没了。
于是立刻、马上登录阿里云,找到 Mongodb 云服务,找到最近一次备份(早上6点钟全量备份的),总大小60GB,立刻操作回滚。
滴答、滴答,经过漫长40多分钟等待。最终终于恢复回来了。
复盘
因为首次启动日本到中国区的同步时,使用的全量+增量的配置方式,就是这种同步方式会清空目标端的所有库,所以当我们重新启动时,就出现了这个灵动了一幕。
该故事改编自真实事故。
通过这件事情得到的教训,重要的一定要进行数据,备份、备份、备份,未知的事情不可轻敌呀,要存有敬畏之心。
文章作者 Bing
上次更新 2021-12-03