不用代码也能爬虫?EasySpider轻松教你抓取数据

文章目录
【注意】最后更新于 September 4, 2024,文中内容可能已过时,请谨慎使用。
你是否曾经为获取网站数据头疼不已?
或者你想要分析竞争对手的价格策略,却因为不会编程而束手无策?
—— EasySpider 一个无需编程的可视化爬虫工具。
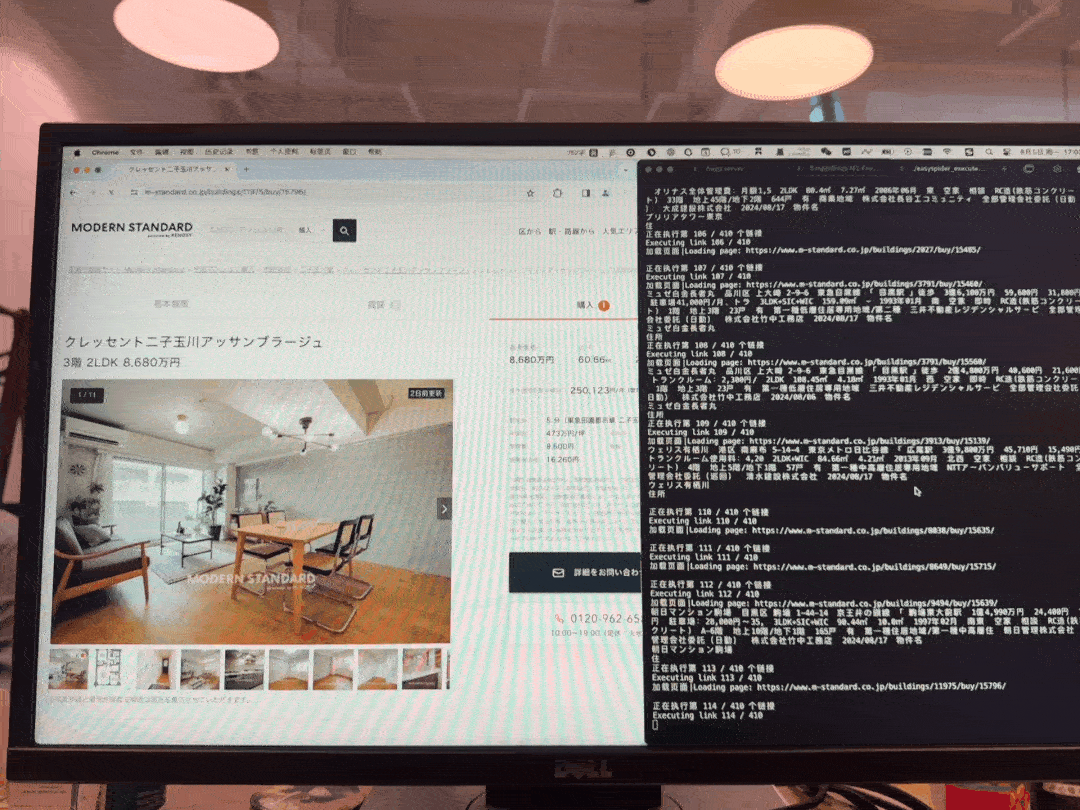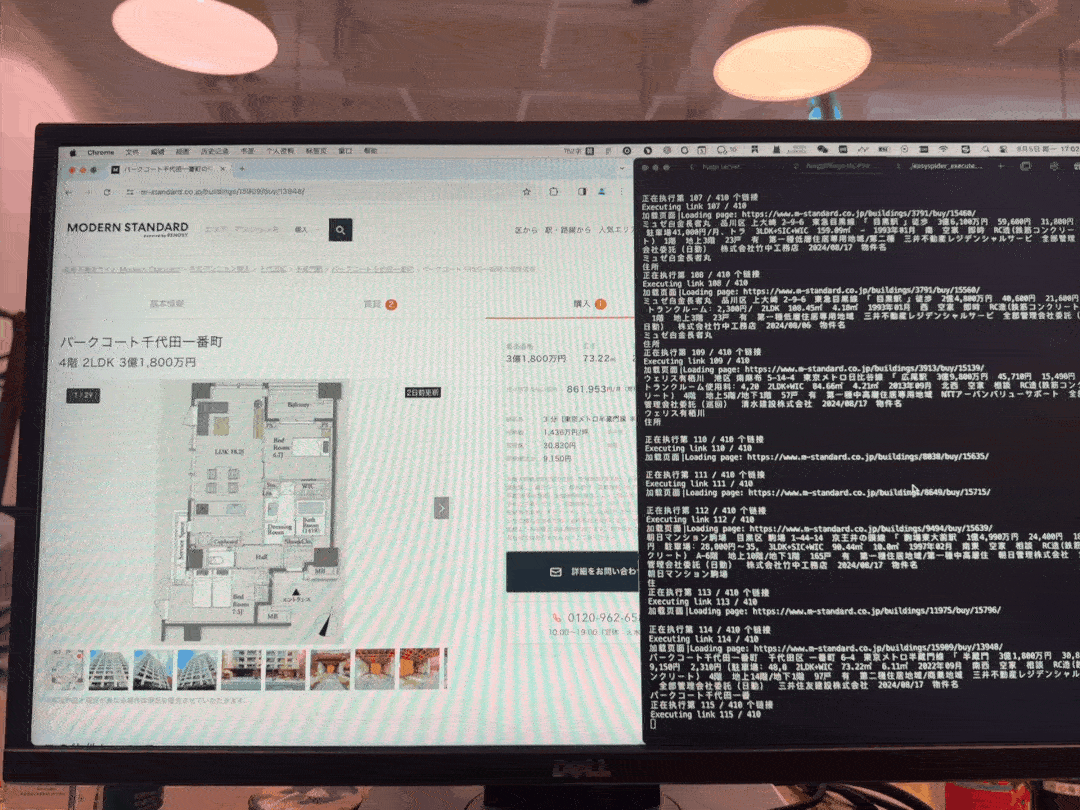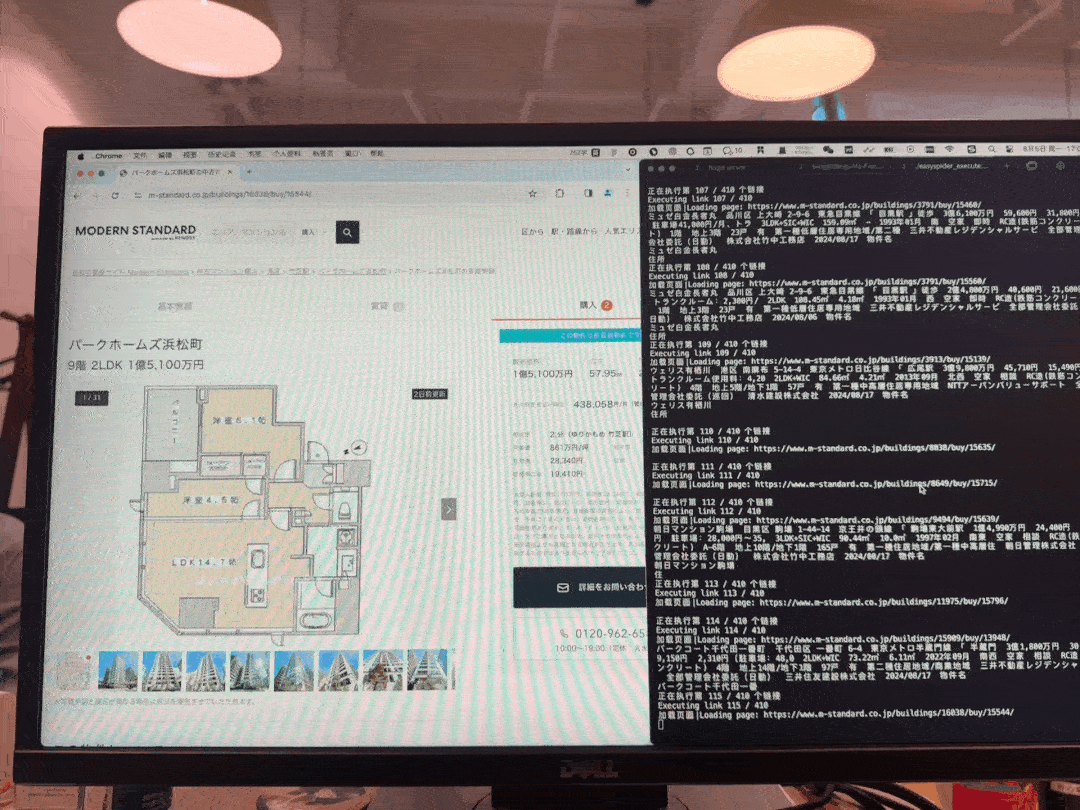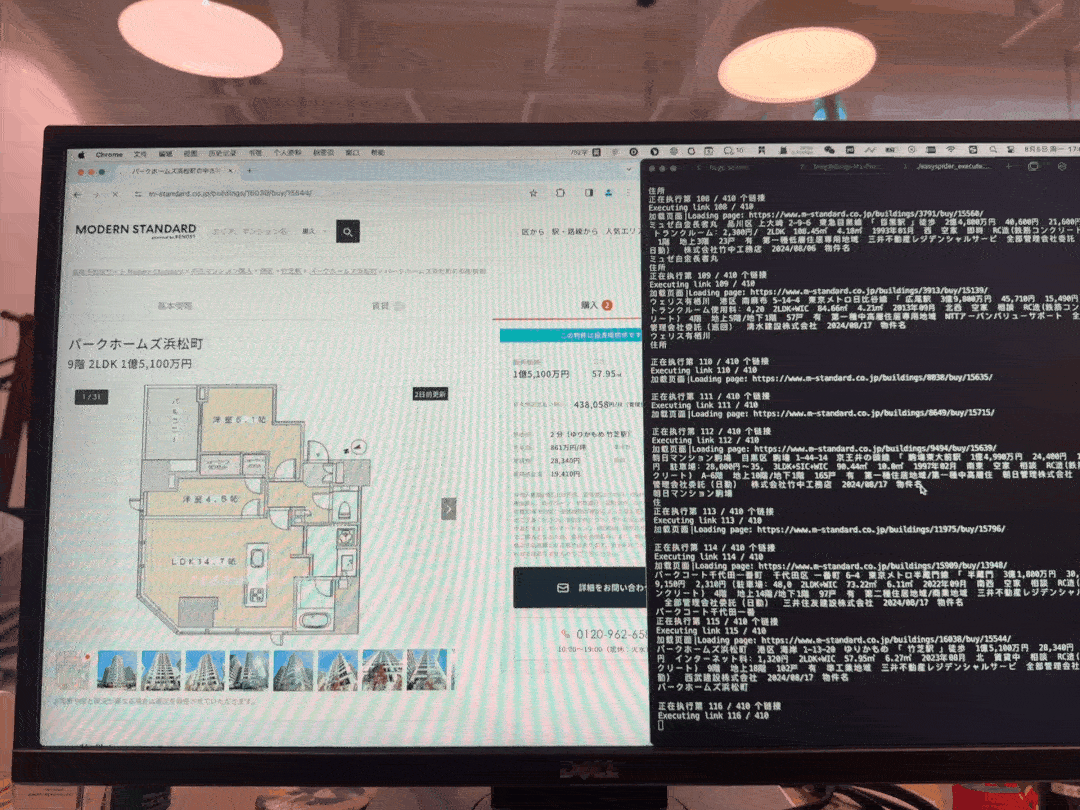
以下是花费约2天时间研究一下出来的采集成果,采集过程效果图。
[!warning]
此示例是采集自家集团公司网站数据,请在遵守法律法规下使用。
1.介绍EasySpider
一个可视化浏览器自动化测试/数据采集/爬虫软件,可以使用图形化界面,无代码可视化的设计和执行任务。只需要在网页上选择自己想要操作的内容并根据提示框操作即可完成任务的设计和执行。同时软件还可以单独以命令行的方式进行执行,从而可以很方便的嵌入到其他系统中—-摘自 Github 原文介绍
这么神的利器,出自浙大学生「王乃博」毕业论文,且完全开源。
2.演示示例
示例一
如何使用EasySpider完成一个简单的数据抓取任务,可以分为以下几个步骤:
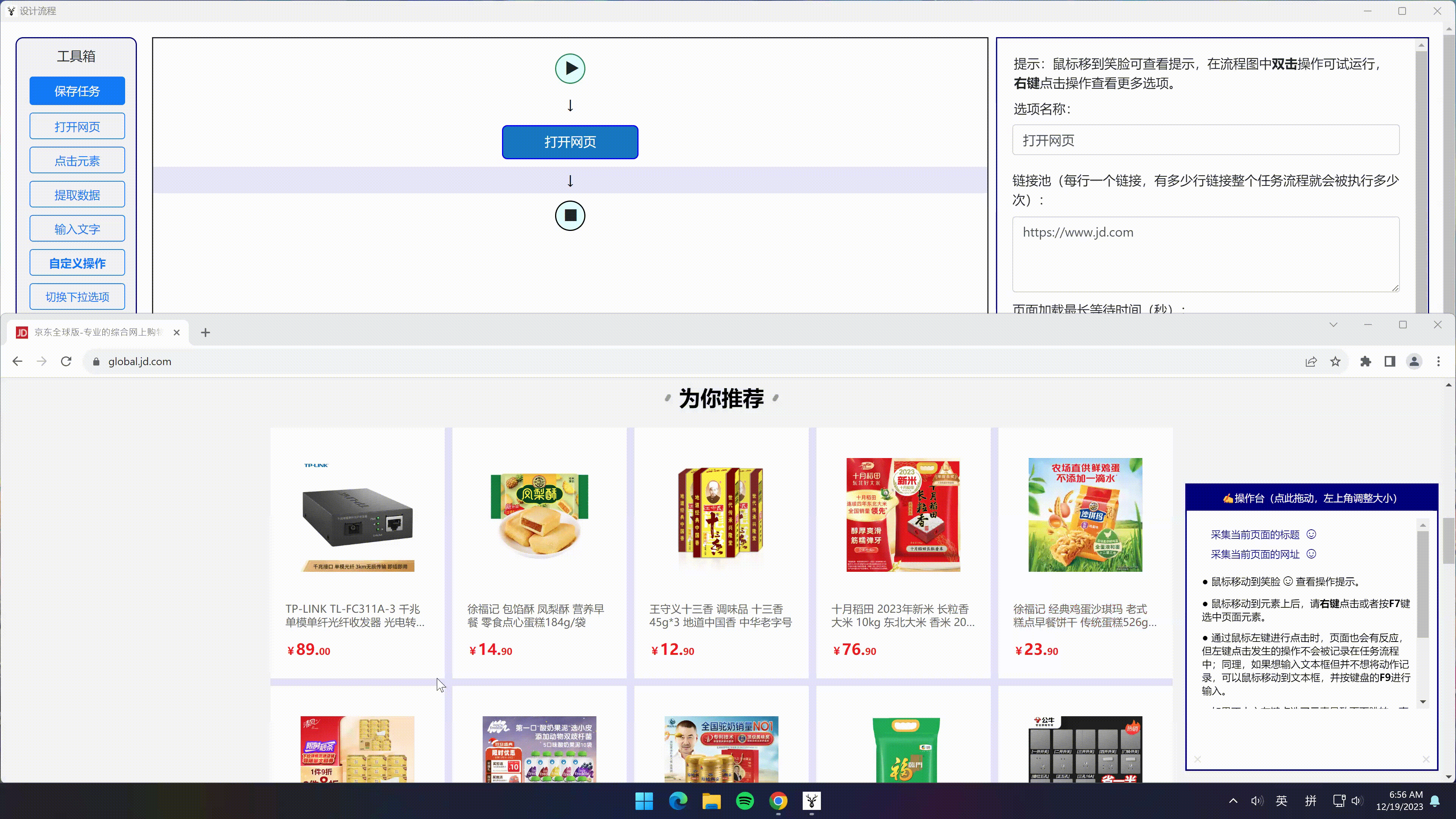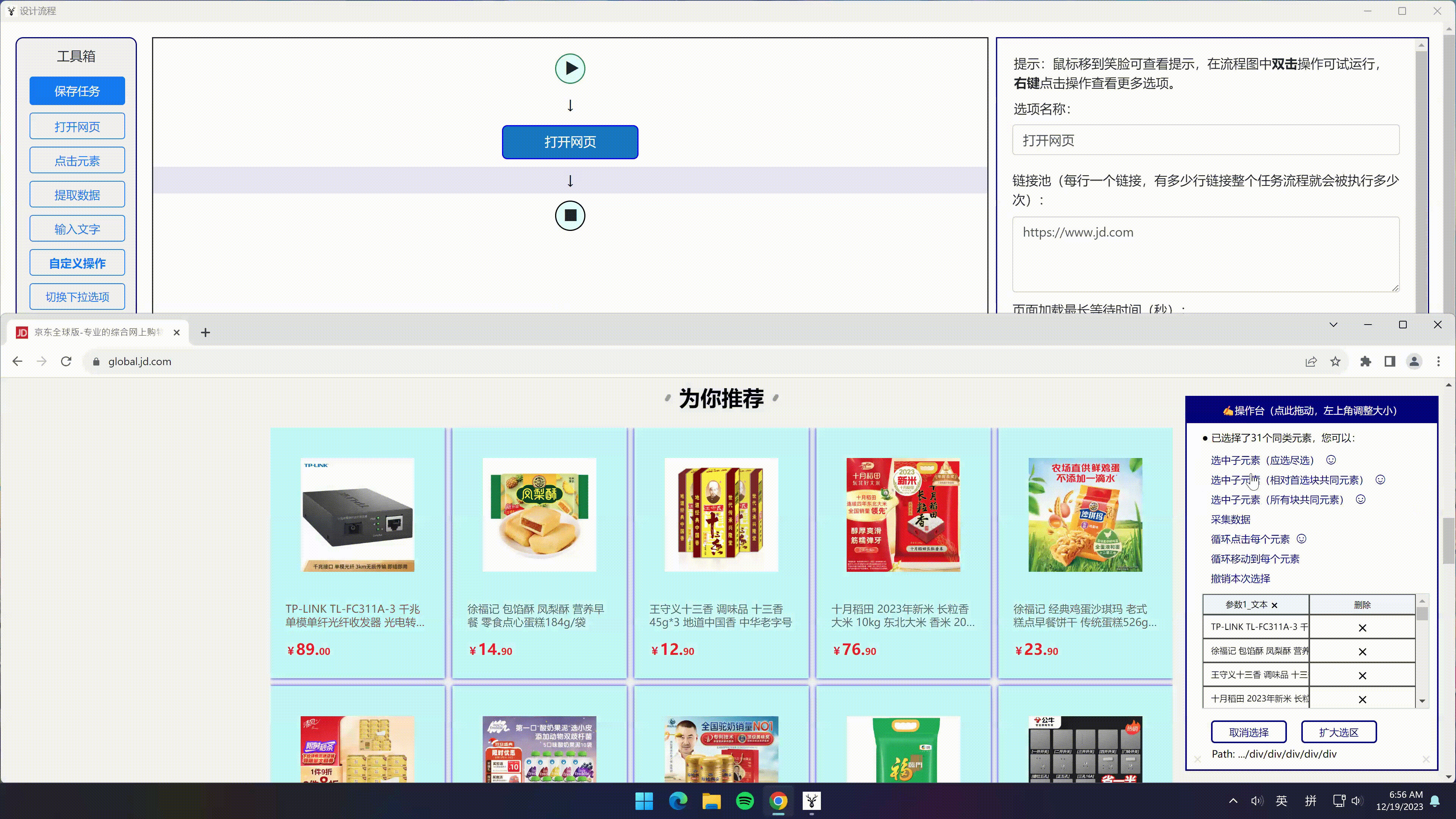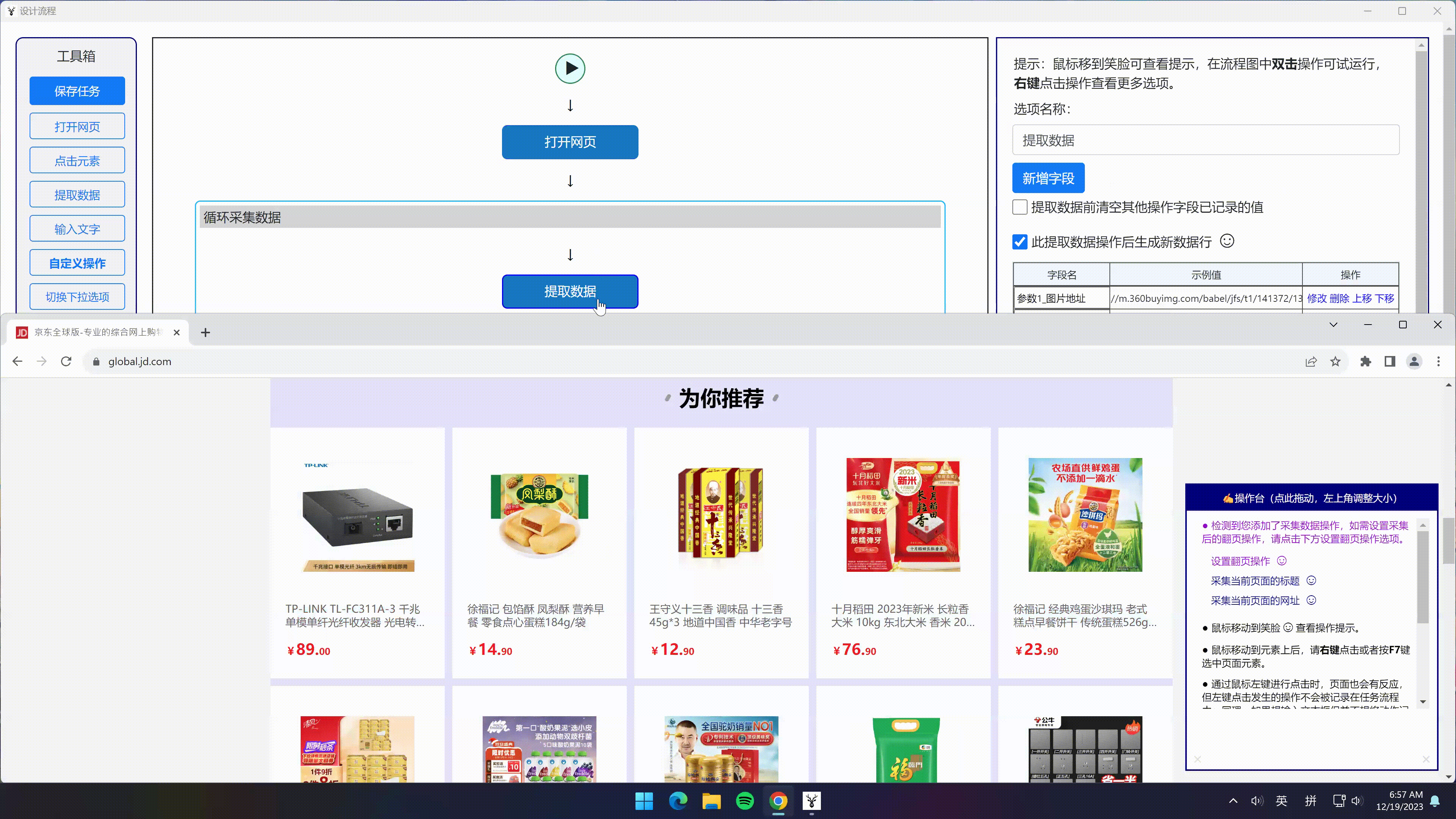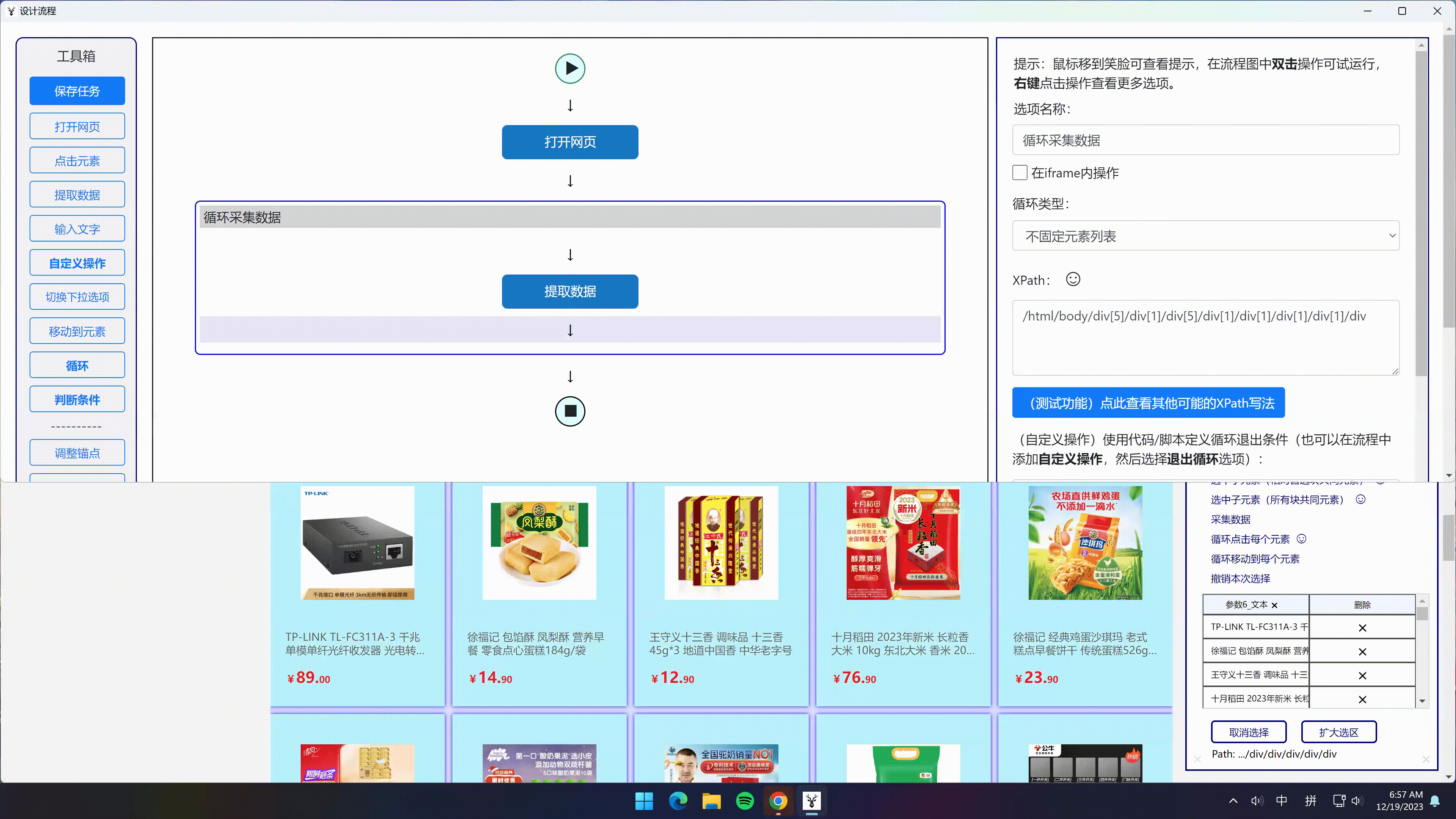
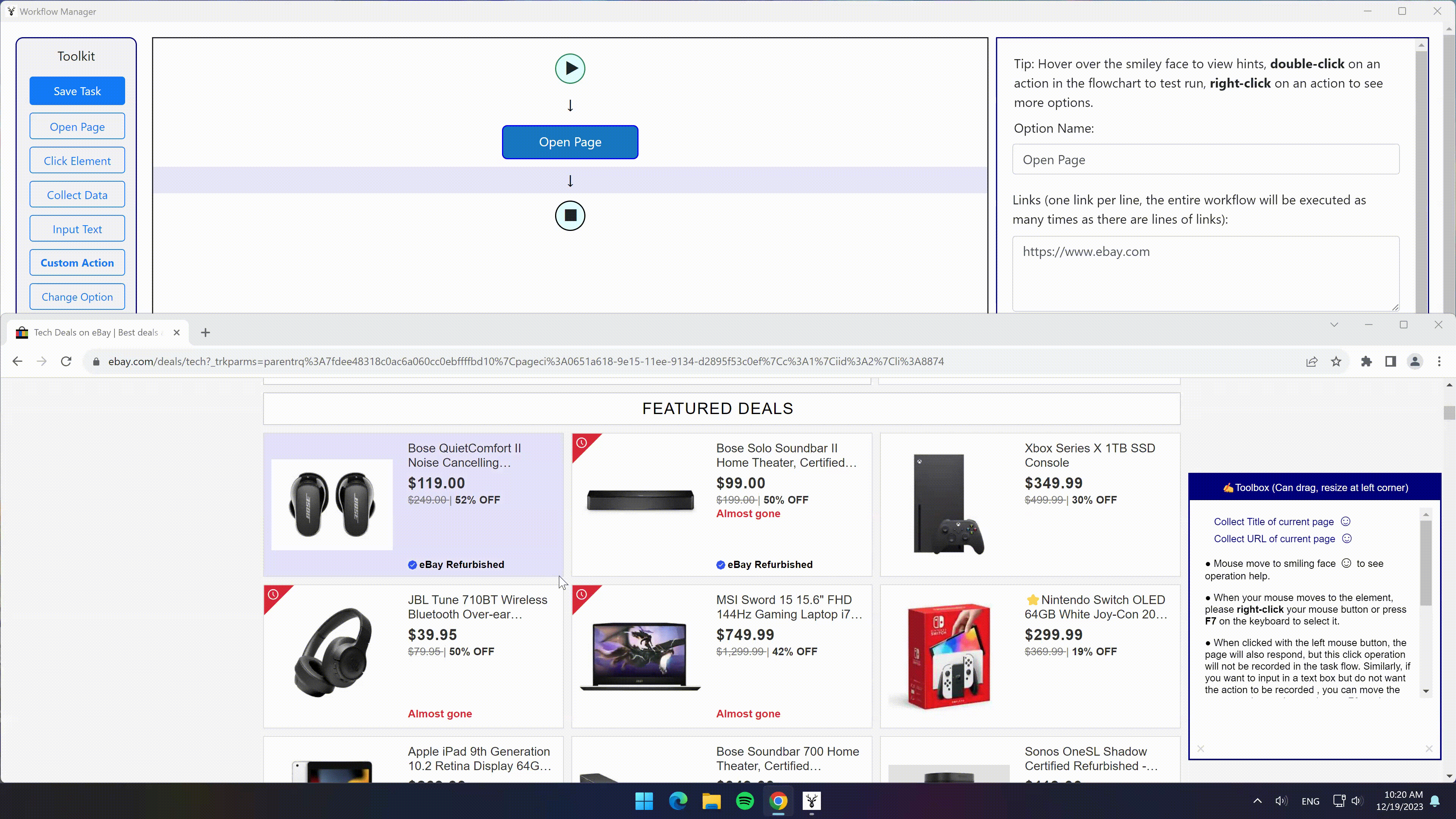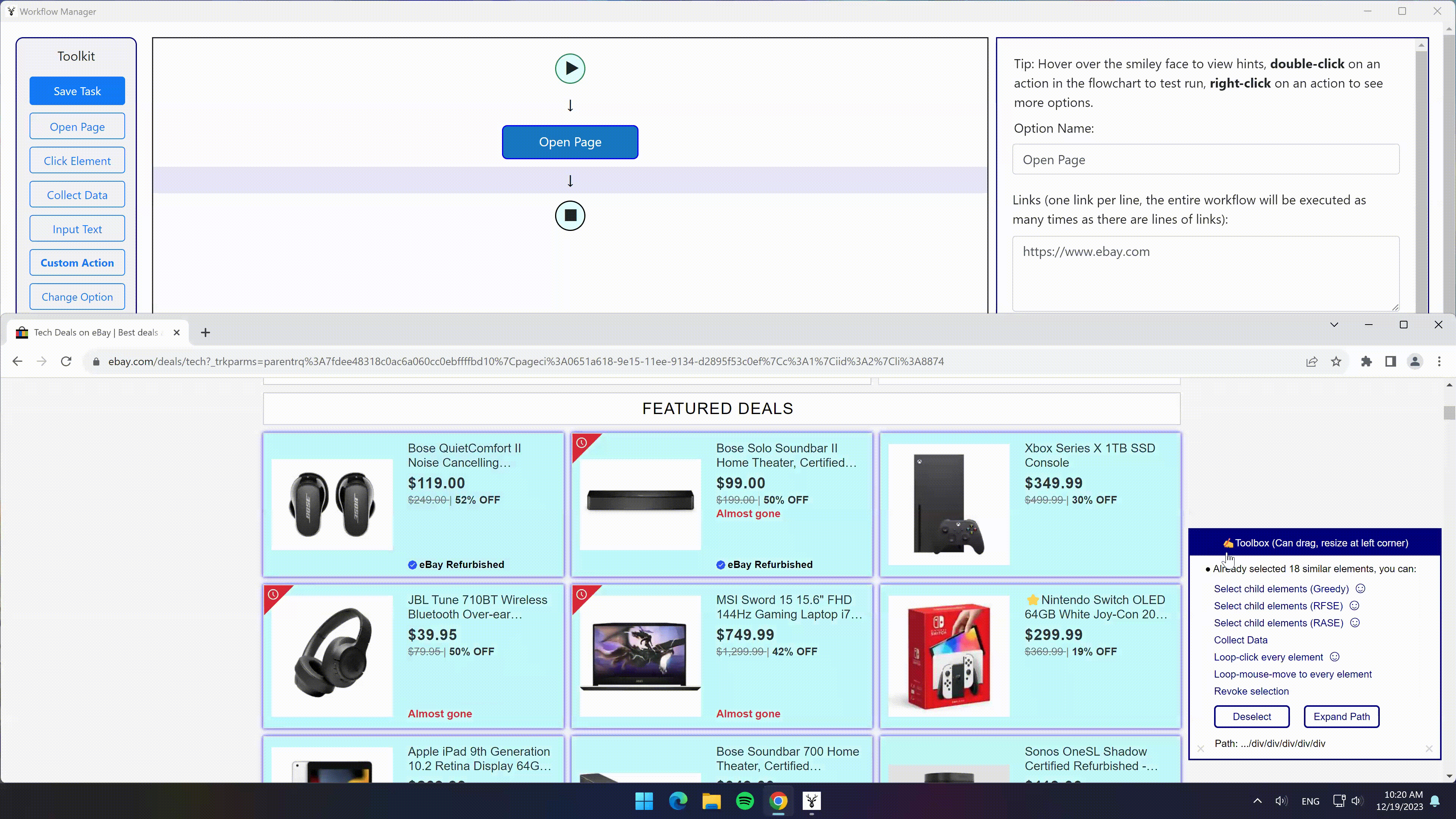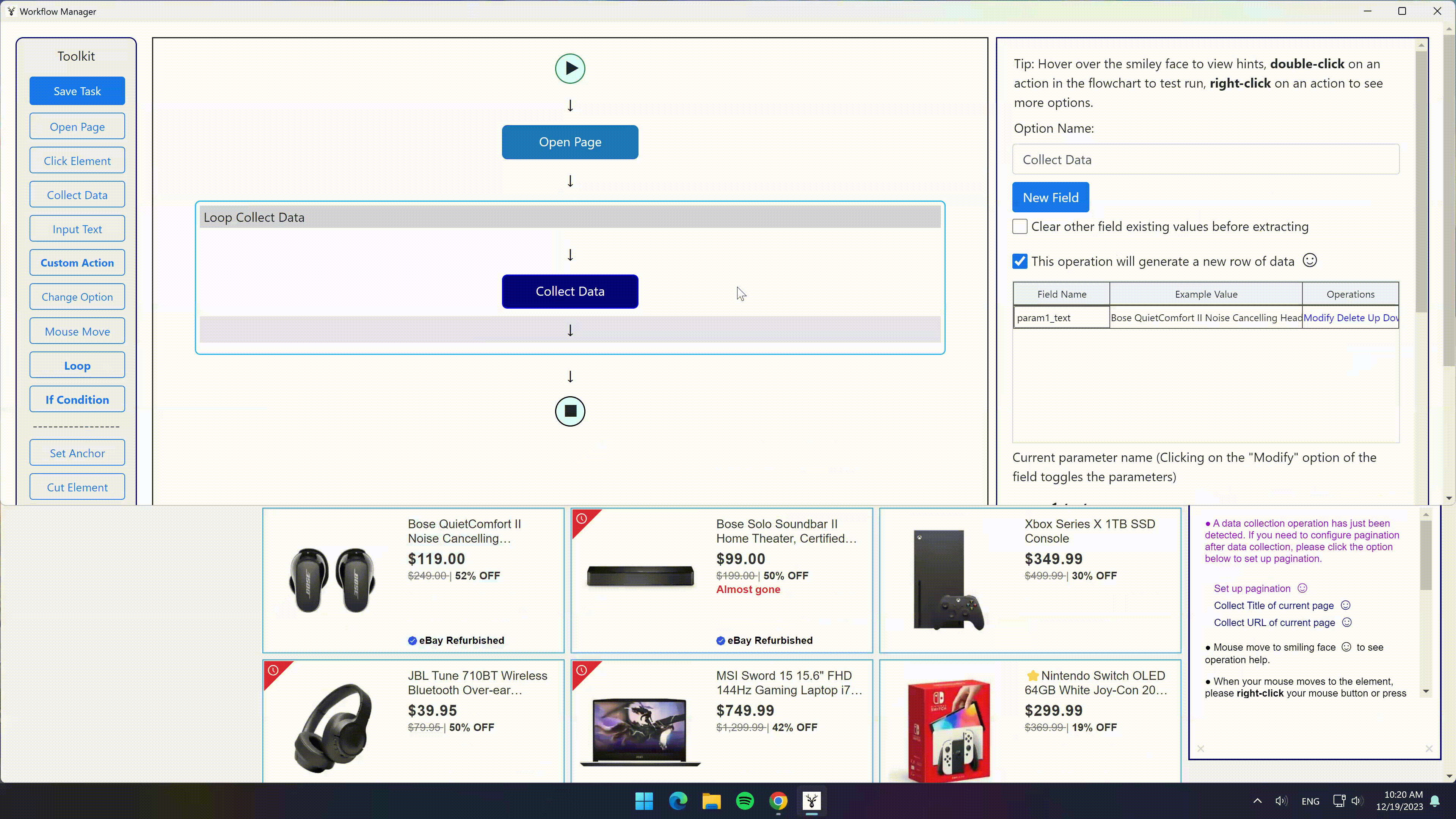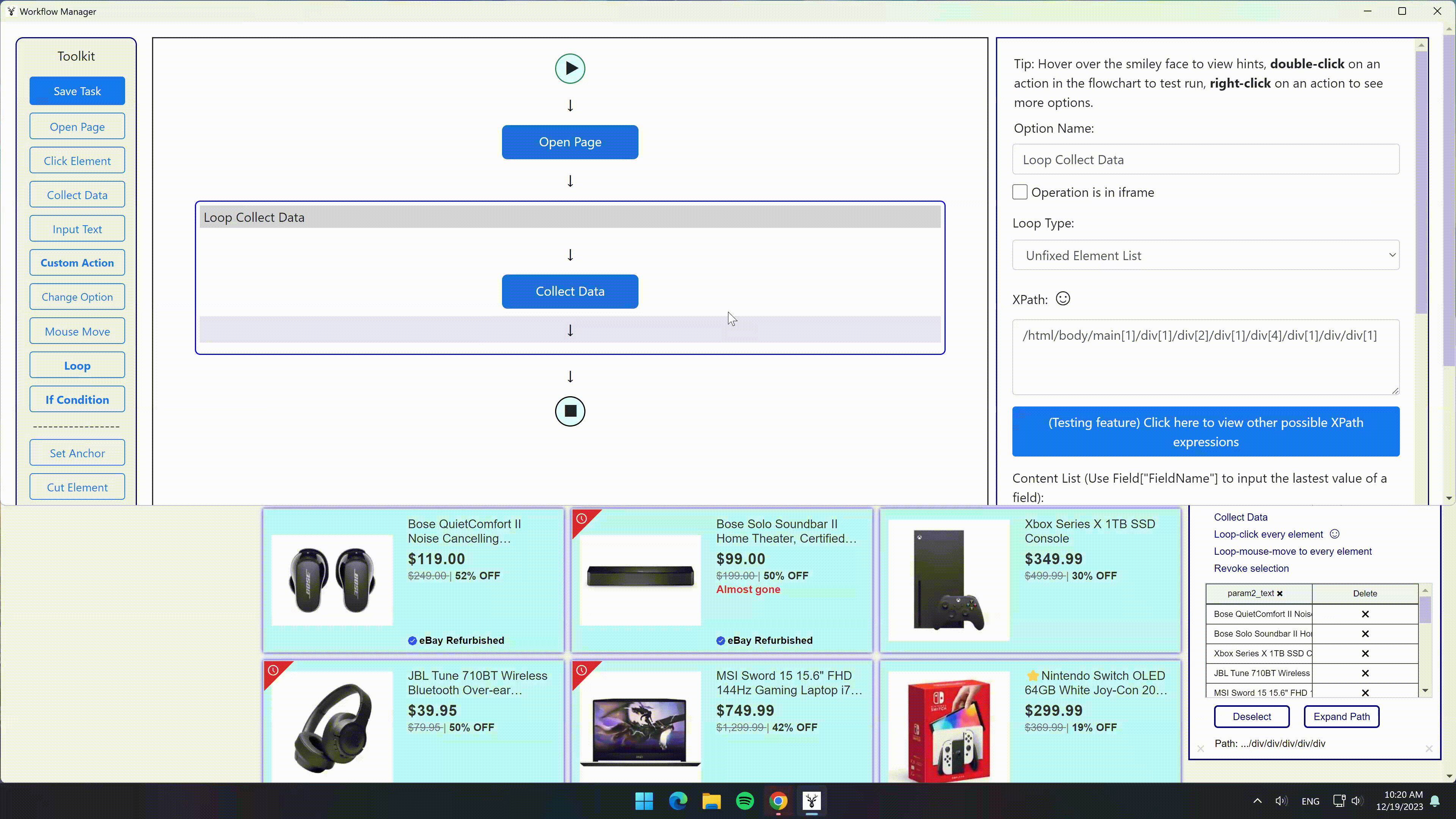
- 选中一个大商品块,软件自动检测到同类型商品块
- 点击“选中全部”选项 -> 点击“选中子元素”选项 -> 点击“采集数据”选项
- 即可采集到所有商品的所有信息,并分成不同字段保存
示例二
选中一个商品标题,同类型标题会被自动匹配,点击“选中全部”选项 -> 点击“采集数据”选项,即可采集到所有商品的标题信息。
同时,选中全部后如果选择“循环点击每个元素”选项,即可自动打开每个商品的详情页,然后可以再继续设置采集详情页的信息。
3.使用感受
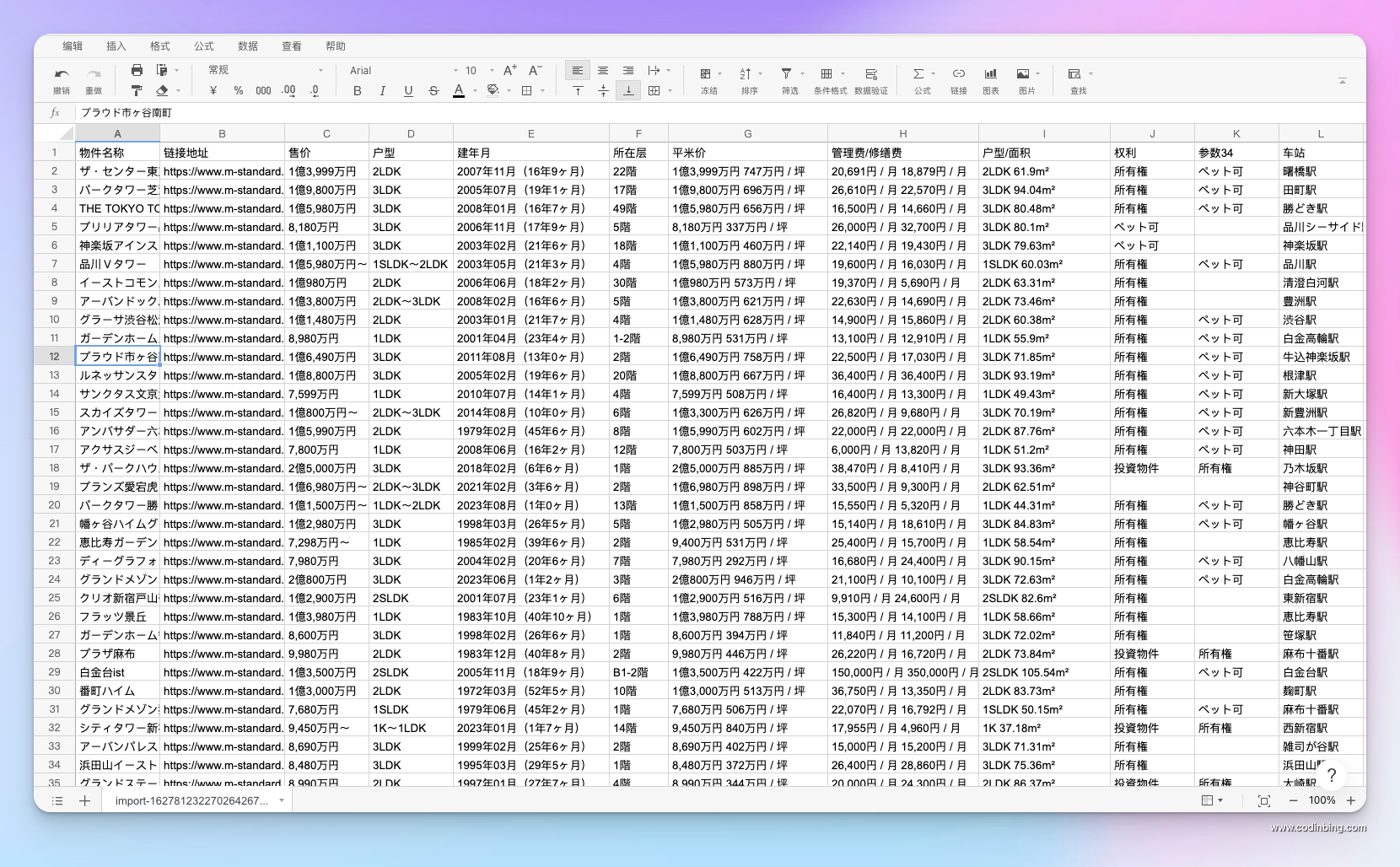
此图片是我采集自家集团公司网站数据,花费了一天工时看完了EasySpider介绍 - 中国地震台网采集案例一个视频教程示例,编写加调试差不多花费3个小时左右,采集了30分钟左右,单线程400套左右房源的抓取任务。
其中我没约到很高级反爬策略,如验证码等行为交互的阻碍,这也是顺利的原因之一,但有遇到访问过多频次跳转其他页面问题,分两次任务一次1~20页,第二次任务20~结尾页,也就搞定了。
其中蛮重要的一点,我认为还是你的需求到完成这个需要的逻辑拆解:
- 你需要的数据格式式样书是什么或者定义出你的数据格式
- 根据你的需求,可拆解为几次爬取任务,才能实现目标数据
- 设计你的抓取任务,调试任务,查看采集数据是否符合目标数据
以为我的本次结果为例:
- 需求数据式样书定义,我的数据仕样书
| 物件名称 | 售价 | 户型 | 建年月 | 所在层 |
|---|---|---|---|---|
| ザ・センター東京 | 1億3,999万円 | 2LDK | 2007年11月 | 22階 |
| … | … | … | … | … |
- 我的任务设计拆分
- 采集全站物件链接
- 根据链接采集物件详情页数据
- 执行采集任务
执行采集数据不会花费多长时间,但是设计爬取任务和调试还是蛮花费时间,需要有一定的逻辑懂 xpath 会节省一定时间,选中子元素,选中需采集的数据,和最终预期结果保持一致(以列形式按多行格式存储)是一件蛮有技巧的事情。
还有可能网站有一定的反爬机制,官方也提供一定的绕过机制,如切换IP池和输入验证码等形式,但这些需要花费你的一定工数处理。
最后 EasySpider 真是太强大了,图形化设计任务简单易用,适合所有人(包括非技术人员)学习和使用的工具 👍👍👍
最后感谢阅读,希望本文对你有所帮助。
帮助文档
文章作者 BING
上次更新 2024-09-04